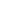案例与数据:
数据大脑中预制了多种分类算法,分类算法可以用来寻找未知事物的发生规律,并辅助人类进行认知。同时数据大脑可以根据机器学习结果形成预测模型,用来进行预测。
根据国家提供某地区人口中糖尿病的发病数据,希望了解到发病率较高的病例普遍伴随什么样的症状。能否通过当前体检数据预测发病概率?
据数据中提供的近800个研究对象,9个属性,部分数据属性信息如下:

运用数据大脑组件中EXCEL组件读取EXCEL文件中的病例数据,用数据库组件读取数据库中的数据。使用的“类型标定”和“异常数据过滤”组件对病例数据中不规范的数据进行预处理,处理完成的数据再使用随机森林决策树算法组件对数据进行训练生成决策树,自动从近800个数据中随机抽取N个作为单棵树的训练样本。 数据大脑自动根据数据集中的9个属性,每棵决策树随机选择最好的属性进行分裂,每棵树都一直这样分裂下去,直到该节点的所有训练数据都属于同一类,数据大脑自动完成计算并生成模型和结果。 分析结果: 通过随机森林决策树分析该数据集的结果如上图所示,该分析得出两个结果: 1、在多种因素中分析出“血糖”对实验结果影响最大。 2、通过移除影响最大的因素,调查剩下的诸因素中影响最大因素。经分析和研究表明剩下的因素中对结果影响大小排序为: 体质指数>年龄>怀孕次数>胰岛素>皮脂厚度>糖尿病家族血统 使用数据大脑随机森林决策树算法进行机器学习并计算出一个模型,该模型在该数据量下的准确度为75.7183%。通过构建模型,可以直接带入体检数据,数据大脑可以预测该样本致病的概率。能够帮助人们更加科学地认知疾病的病因,分析健康行为的依据。 决策树是机器学习领域中一种非常重要的分类器,算法通过训练数据来构建一棵用于分类的树,从而对未知数据进行高效分类。而随机森林是由多个决策树组成的。让这些决策树随机生长,最后选出************的决策树模型作为分类模型。 (1)训练每棵树时,从全部训练样本中选取一个子集进行训练。用剩余的数据进行评测,评估其误差; (2)在每个节点,随机选取所有属性的一个子集,用来计算******分割方式。最终得到结果相似的聚集在一起以及结果不相似的聚集在一起。 在工艺分析,配方分析,人力分析,风险辨识中应用广泛。分析过程:



适用范围:
在多种因素中分析对实验结果影响最大的特定因素。
对诸多因素的分析中影响最大的因素已有所进展,需调查剩下的因素中影响最大因素。