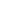国工数据大脑之双样本Poisson检验与LIMS 系统的融合应用
近年来,数据挖掘引起了信息产业界的极大关注,其主要原因是企业在生产、运营过程中产生大量的数据,迫切的需要将这些数据转换成有用的信息和知识。获取的信息和知识可以广泛用于各种应用,包括商务管理,生产控制,市场分析,工程设计和科学探索等。国工智能实验室LIMS系统融合了国工智能数据大脑平台,平台内提供上百种统计学相关算法及机器学习算法;通过这些算法对企业数据进行分类分析、聚类分析、关联分析、预测分析,挖掘数据潜在价值,探索人力无法探知的规律,提高企业产品附加值及行业竞争力,助力企业快速发展。本次案例就双样本Poisson检验与实验室LIMS系统相融合进行探讨及应用举例。某企业质检实验室需要检验A、B两种实验样品的缺陷数量,在相同的检验方案条件下分别用A、B两种实验样品进行检验,得到的检验结果如图1所示,试分析在相同检验方案情况下,A、B两种实验样品的缺陷出现率。 
图1 检验结果
使用国工数据大Excel读取组件,将数据集映射到系统中。
图2 Excel读取
再通过拖拽的方式将双样本Poisson率检验分析组件与Excel读取链接到一起。使用集成好算法的双样本Poisson分析组件进行数据的Poisson分析处理,对组件参数进行设置,因素字段配置为factor,结果值配置为检验结果result,显著性水平设置为0.05,单击运行,从调试面板中查看分析结果。
图3 双样本Poisson率校验分析组件及参数配置
图4 分析结果
从图4中运用双样本Poisson分析得出的结果可以看出,由于 p 值 0.157 大于显著性水平(用 α 或 alpha 表示)0.05,因此分析员否定原假设并得出两个样本缺陷发生率不同的结论。95% 置信区间表明,样本 B 的缺陷率可能高于样本 A 的缺陷率。 国工数据大脑平台可直接获取实验室LIMS系统中的实验数据,直接将实验数据对接到创建好的双样本Poisson检验模型中,根据得出的分析结果自动对报告进行判定,代替人工判定;并将存在缺陷显著性差异的报告重点推送给相关领导引起重视。根据领导对存在显著性差异报告的处理,可自动触发二次检验流程等操作。实验室系统中的双样本Poisson检验用于比较两个遵循Poisson分布的总体的均值或发生率以确定它们是否存在显著差异的假设检验。Poisson分布可为时间在给定时间内发生次数、面积、体积或其他观测空间建模。例如,实验员检查 2 个批次(A 和 B)上每箱实验样本的缺陷数量。一个样品可能会有多个缺陷,对于批次 A,每箱包含 10 个样本。实验员总共抽取 50 箱,共发现 122 个缺陷。对于批次 B,每箱包含 15 个毛巾。实验员总共抽取 50 箱,共发现 132 个缺陷。对于批次 A,总发生次数为 122,原因是实验员发现了 122 个缺陷。对于批次 B,此数字为 132,原因是实验员发现了 132 个缺陷。对于这两个批次,样本数量 (N) 均为 50,原因是实验员对于这两个批次均抽取了 50 箱。为了确定每个样本的缺陷数,实验员对批次 A 使用观测值长度 10,原因是每箱有 10 个样本。对于批次 B,检查员使用观测值长度 15。对于批次 A,采样率为(总发生次数 / N)/(观测值长度)= (112/50) / 10 = 0.224。对于批次 B,采样率为 (132/50) / 15 = 0.176。因此,批次 A 中每个样本平均有 0.244 个缺陷,批次 B 中每个样本平均有 0.176 个缺陷。由于实验员输入的观测值长度不为 1,因此数据大脑也将计算样本均值。对于批次 A,样本均值为(总发生次数 / N)= 112/50 = 2.24。对于批次 B,样本均值为 132/50 = 2.64。样本均值描述每箱的平均缺陷数。但是,由于各箱中含有不同数量的实验样本,因此采样率是更有用的统计量。