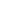首先,我们把这一类以“判断”为输出结果的问题,统一归纳为假设检验[2]问题,处理这类问题的方法是:先把某个结论当成一种假设(统计学上也称为原假设,null hypothesis, 记为H0,与之对应的称为备择假设,alternative hypothesis,记为Ha),然后收集样本,根据样本观测值的情况,运用统计分析的方法对假设进行检验,并做出判断。
以刚才提到的那位女士为例,我们可以通过试验的方法来判断她所声称的超能力是否属实,如果这位女士品尝了6杯奶茶后,并且她的判断都是正确的话,我们就可能从原先怀疑转为相信她的超能力了,因为如果假设她不具备这种超能力,而是全靠猜,那么她6次全部猜对的概率只有(1/2)6×100%≈1.6%,这是一个非常小的概率。
由此可以看出,假设检验的基本原理是,在接受假设成立的情况下,计算样本(或事件)发生的概率,如果得出的是一个非常小的概率,则我们开始从接受假设成立变为拒绝假设成立。可是,这个概率到底要多小,我们才会做出倾向于拒绝假设的判断呢?这个值的定义是依据行业领域或者应用场景而定的,一般在化工行业,这个值大部分取为5%,但是在一些高精尖领域或者健康安全相关度高的行业,如医药、航空等行业,这个值更能会取得更小,比如1‰,对于这个值,在统计学上有其专属的名称和符号,叫做显著性水平,记为α,与之相对应的1-α被称之为置信水平。
那么,为什么在某些行业领域对于α的取值要非常小呢?再以刚才的女士品茶为例,假设一家公司准备以非常高的薪水聘用这个具有超能力的女士作为他们的品茶官,招聘人员对她所声称的技能的检验将会更加严格了,可能需要连续10次不出现差错,他们才可以放心地录用该女士,所以,这里我们就体会到了,α取值越小,是为了越好地防止做出错误的决策而造成决策风险。

图1:女士品茶概率分布情况
(设定α=0.05,则如果女士能9次及以上给出正确判断,我们就没有办法拒绝她具有超能力)